The f04cb mystery so far
The f04cb41f154db2f05a4a subreddit is one of the Internet’s many mysteries. It has been listed amongst the weirdest, creepiest, most insane subreddits ever, and made an appearance in The Daily Telegraph’s list of the most bizarre subreddits ever created.
In short, the cryptic messages on the subreddit have received a great deal of attention, yet little progress has been made as to what they might mean. So what do we know so far?
- The posts began back in 2012 and comprise of lists of eight character strings: “RoVdTYF5 ReReSYJ1 TIZ1SYN3 SID5RoJb” with numeric titles
- This format was deviated from just twice, when f04cb posted the plaintext “help” and “please help us”
- Also, one of the posts is simply titled zero
- The subreddit’s background used to feature the Reddit mascot with a bleeding eye, but reverted back to default at some point
Theories as to what the messages might signify ranged from links to a Russians lasergun website, speculations about leaked data from the Tehran Stock Exchange, to botnet command & control instructions.
Many attempts were made to break the code, some more determined than others. By May 2015, the community had come up with some promising ideas, most of which originate from Reddit user ZtriS:
- The post titles are UNIX timestamps, roughly approximate to the actual post date
- A combination of Base64 decode and Caesar cipher translates the ciphertext into numbers
- The final digit of the timestamp is the Caesar shift value
Still, not everyone agreed that this was the right approach, and the next step to take in the puzzle was totally unclear. At that point, the cryptic posts stopped coming, and with no further progress made, interest in solving the mystery almost completely died out…
…until 20 days ago, when a post following the familiar format appeared. The rebirth of f04cb was echoed over reddit and was noted by a friend, who sent the ciphertext to me. We first read over all pertinent information before attempting to make some headway on this tantalising mystery.
First of all, it was pretty clear that the Caesar + Base64 approach was the right thing to do, particularly because shifting by the last digit of the timestamp unveiled numbers every time. For us, the obvious next step was to quickly hack up some Python to decipher all the posts this way, and then closely inspect the output. First, a Caesar cipher function:
def caesar_decrypt(message, n):
result = ''
key = 'abcdefghijklmnopqrstuvwxyz'
for l in message:
try:
i = (key.index(l.lower()) - n) % 26
if l.isupper():
result += key[i].upper()
else:
result += key[i]
except ValueError:
result += l
return resultIn the posts, only letters are shifted whilst numbers and symbols remain intact, so we didn’t bother with an ordinal transformation. Instead we hardcoded the key and ensured that uppercase characters remained uppercase for the Base64 decode. A few of the posts made the Python Base64 module complain of ‘Incorrect Padding’, which indicated that the user had manually deleted some of the =’s from the ends of the posts – perhaps to disguise the nature of the ciphertext – although this was inconsistently done. We had to add the missing padding with a useful function:
def decode_base64(data):
missing_padding = 4 - len(data) % 4
if missing_padding:
data += b'=' * missing_padding
return base64.decodestring(data)Applying those two functions to the posts, with timestamp[-1] as the second argument to caesar_shift, decoded them all to numbers of varying lengths. One more thing: f04cb’s comments and sidebar lack timestamp titles, so we needed to brute force the Caesar shift value, although ‘brute force’ is an overstatement when describing trying out just ten numbers:
def f04cb_bruteforce(message):
for x in range(0, 10):
caesared = caesar_decrypt(message, x)
base64d = decode_base64(caesared)
if base64d.isdigit():
return base64d
else:
passWhile crawling all of f04cb’s content, we logged the actual timestamp of the posts. This turned out to be a minor item of interest: although it took him or her 174 seconds between generating the first post’s timestamp title and posting to reddit – and over a minute in the next few subsequent posts – the last 4 posts all took less than 8 seconds, with the most recent one a lightning 4 seconds. f04cb is getting faster.
So what we had were about 3500 apparently random numbers, with no patterns to be seen. We tried a few common things on those numbers, such as converting each pair of digits to letters mod 26, which gave us nonsense like this:
stimqekbgbljqoneuvutnvfikticfrrkcslzwegkszdxqrsxvrndoftkfvilcmnydobhl
It struck us that if the numbers really were randomly distributed, there was not much we could do with them. Knowing that eyes alone cannot be trusted, we performed a chi-square test against the uniform distribution, which confirmed that the numbers are indeed randomly distributed.
Now, this did not necessarily mean that we were at the end of our quest. In cryptography, a completely random ciphertext screams ‘One Time Pad’. The plaintext is found by XORing the ciphertext with a randomly-generated key. We tried XORing posts with the sidebar text, and with other posts, all to no avail.
We read about the VENONA Project, in which USA cryptanalysts were able to crack a Soviet one-time pad, but only because the Soviets reused the same key, and because of a method called ‘crib-dragging’, which involves painstakingly trying out common phrases until one slots into the correct position. However, since we do not know anything about a hypothetical underlying f04cb plaintext, that method won’t help us. Furthermore, almost all f04cb messages are of different lengths, so looking for some kind of common key would appear a futile effort. If the key were something shorter and guessable, say a word or phrase, then the ciphertext would not be randomly distributed as it is.
Yet the mystery was not over. We got in contact with ZtriS, who pointed out an intriguing property of the ciphertext: when converted to hexadecimal, it’s no longer random. We were sceptical at first, so we did a little experiment to check.
First, by reversing the decryption procedure above, we had a program capable of generating ciphertext indistinguishable to that posted by f04cb:
import base64, random, re, time
MIN_LENGTH = 15
MAX_LENGTH = 100
timestamp = str(int(time.time()))
def caesar_encrypt(message, n):
result = ''
key = 'abcdefghijklmnopqrstuvwxyz'
for l in message:
try:
i = (key.index(l.lower()) + n) % 26
if l.isupper():
result += key[i].upper()
else:
result += key[i]
except ValueError:
result += l
return result
message = []
for x in range(0, random.randint(MIN_LENGTH, MAX_LENGTH)):
message += str(random.randint(1, 10))
b64d = base64.b64encode(''.join(message))
caesared = caesar_encrypt(b64d, int(timestamp[-1]))
print(timestamp)
for x in re.findall('........', caesared):
print(x)Next, we generated an amount of fake data equal in length to the original f04cb data, and then performed a Pearson’s correlation after decryption and conversion to hexademical. A coefficient above 39 was the 0.999 confidence interval for non-random data, and while our fake data scored 16.3 (as we would expect for random data), the original data scored 126.2. In other words, while the f04cb numbers look random to the human eye, they are in fact far from it.
Indeed, the non-randomness of the decrypted f04cb data in hex is clear from the marked peaks and troughs of the frequency distribution:
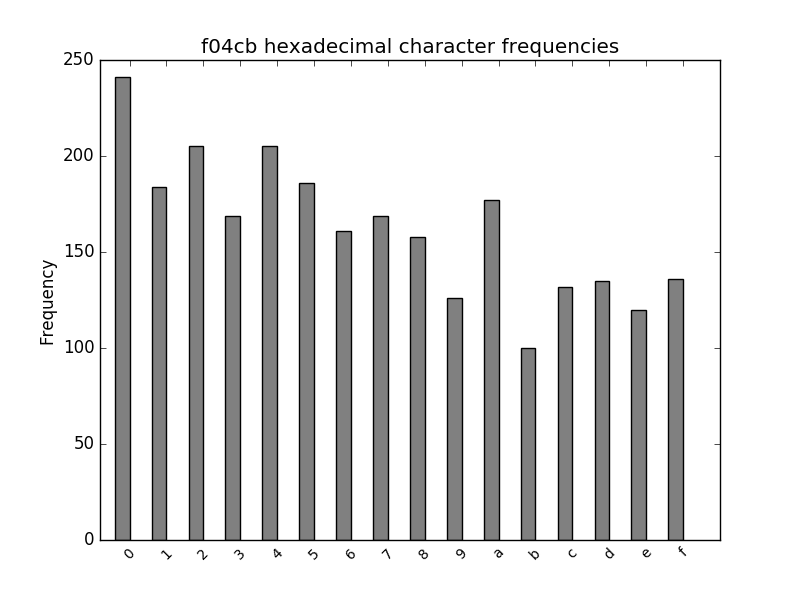
Furthermore, the non-randomness showed up when interpreting the number in any power-of-two base (such as binary or hexadecimal), giving some clue as to an underlying representation. We weren’t sure where to go next, though.
A year and a half later, Reddit user fikuhasdigu fully decrypted the code! Unfortunately the contents are not very interesting.