Three Years of Solving Codewords
- What are the most challenging codeword clues?
- Why does Kenya appear to be full of codeword addicts?
- How many people are even interested in codewords anyway?
My Codeword Solver has now been running for over three years, during which time it has gathered plenty of data about codewords and the people who like to solve them. Recently I open sourced the code and wanted to see what insights could be gleaned from digging through the logs. In the interests of more technically-inclined readers, I will be footnoting the commands I used throughout the article [1].
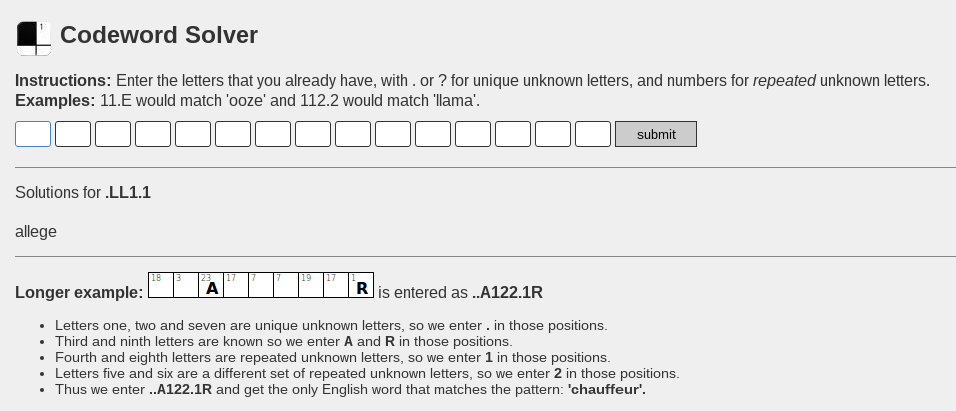
The logs showed about 60,000 unique searches per month [2], from an overall total of 75,000 unique IP addresses [3]. That’s a lot of searches per user on average, which could signify either a small loyal userbase of codeword solvers, or an artificially inflated total due to crawlers and hacking scanners. Since I couldn’t identify that many automated queries, I favour the idea of a loyal userbase.
Which nations like solving codewords the most? Plotting the visitors on the world map shows a very uneven distribution [4]:
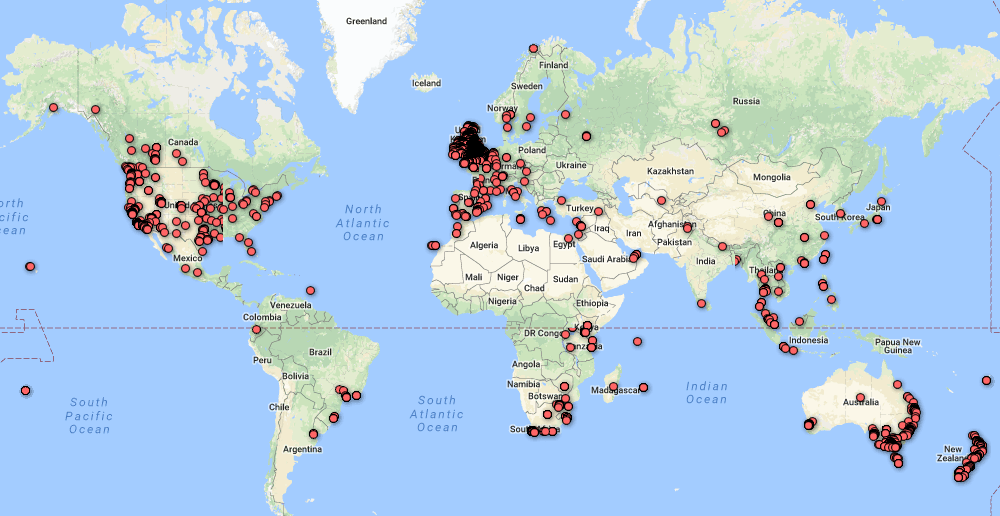
Clearly UK users form the overwhelming majority (over 83%), and a heatmap emphasises this:
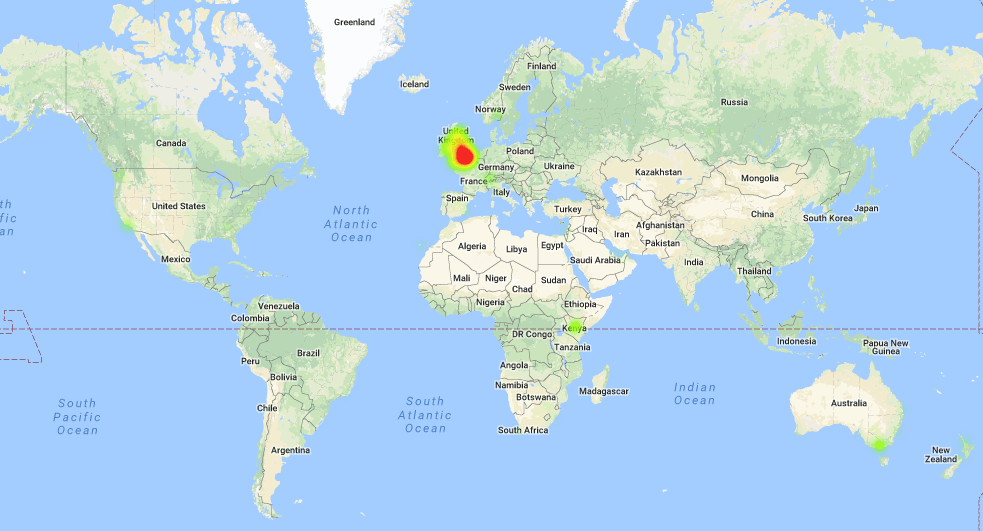
There are faint patches in SE Australia, West Coast USA, and especially Kenya, which merited further investigation. It turns out that Kenya’s most popular newspaper, the Daily Nation, contains a Sunday codeword:

But then again, so do other East African papers, a result of their Commonwealth history. Strangely, on the visitor map many of these countries don’t show any data points at all.
Looking closer at the latitude-longitude data, most of the data points in Kenya are just (1, 38), a wildlife park:
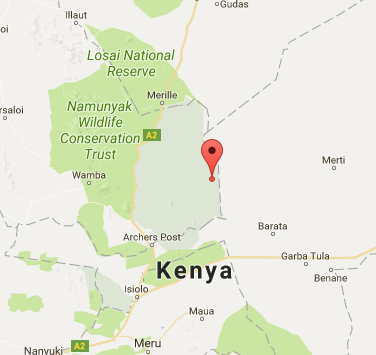
Certainly not where the website traffic originated from. In fact, this effect is probably caused by the inherent difficulty of geolocating African users; for some reason they are pinpointed to a Kenyan wildlife park instead.
Moving onto user devices [5]:
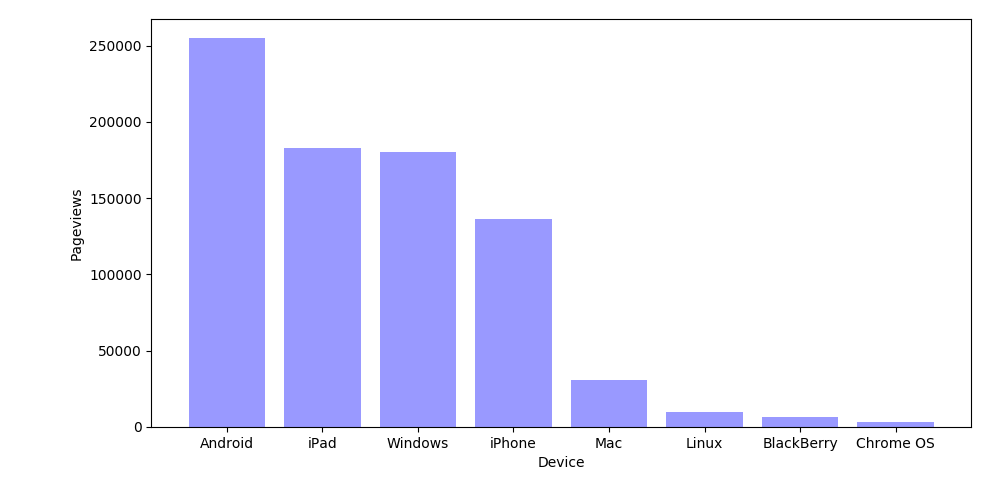
Apple devices make up the majority of the traffic, as do mobile devices in general. This makes sense as people generally like to solve codewords on their couches, not at their computers so iPads are popular for this, especially among an older demographic.
Most interesting is the listing of most common clue searches and corresponding solutions [6]:
411 A..A.A alpaca ankara arcana armada
246 . a i
186 ..1T.1T content fastest justest shutout vastest
180 AAA ?
169 .L.L.. slalom
150 'A=0 ?
145 A..A aqua, aura etc
136 L1.1LL. levelly
130 B.B. babe baby bibs bobs
122 T..W thaw thew trow
113 .1ZZ1..22 dizziness
112 S..SS..S scissors
110 GN... gnarl gnars gnash gnats gnaws gnome
107 .1NI1N. lenient
101 LEE.. leech leeds leeks leers leery
99 .LL1.1 allege
95 ..ZZ... buzzard fuzzing puzzles etc
91 .TI.IT. utility
91 S..B scab serb slab slob snob snub stab stub swab swob
91 .MB..M embalm imbalm
89 ..MA bema coma lima puma soma
88 E.E eke ere eve ewe eye
87 .N.N..N unknown
A few of these are a little suspicious, but most seem to be actual initial clues which foxed a lot of newspaper readers. ‘Slalom’ for instance is the only word matching the pattern ‘.L.L..’, and therefore makes for a prime codeword clue. ‘.N.N..N’ is another really nice one.
I wonder if codewords are still created by hand, or whether computers generate them. The full data here would make it easy to write a program to generate well-balanced codeword puzzles, which I may attempt one rainy day.
Codewords have clearly never caught on that much outside of Britain and a smattering of Commonwealth countries. Perhaps because solving them requires a high level of English language knowledge, and they don’t work so well in other languages. Codewords in languages where words share similar word endings (i.e. Italian) would be too easy. Furthermore, if a lexicon is small, and not full of diverse loanwords like English is, it is hard to create a decent puzzle which contains all the letters of the alphabet.
Still, this doesn’t explain why codewords aren’t popular in the USA. In fact, ‘codeword’ seems to mean something different altogether across the pond.
Footnotes
[1] Initially, pull the Apache access log off the remote server and save all the codeword searches:
scp user@ip:/var/log/apache2/access* .
cat *gz > access.gz
gunzip access.gz
grep \&l92 access.log > outI decided to focus on the last 8 months of data as it alone was 600mb, providing a good sample for faster processing, and data before then used a slightly different format.
[2]
> wc -l out
808936About 100,000 searches per month before removing duplicate searches from the same users. To remove such duplicate searches (field $1 is IP, field $11 is the request):
> awk '{print $1":"$11}' out | sort | uniq | wc -l
508605The duplicate requests are probably due to people clicking the Submit button several times or leaving the page open on a reloading mobile browser.
[3]
> awk '{print $1}' out | sort | uniq | wc -l
74486[4] I used freegeoip, a fantastic API you can run as a local server to get location information about IPs. Asking for JSON objects out of it, I realised later I wanted just a csv file of latitudes and longitudes. I used the rather slow jq command to extract these:
> while read ip; do curl http://localhost:8080/json/$ip >> ips_json; done < ips_unique
> while read obj; do echo $obj | jq '[.latitude, .longitude] | @csv' >> coords.csv; done < ips_jsonThrowing this file into Google’s Fusion Tables gave back the maps.
[5] Hacky command line to clean up the inconsistent OS/user agent field:
> awk -F\" '{print $6}' out | sed -e '/BlackBerry/c\BlackBerry' -e '/BB10/c\BlackBerry' -e '/Android/c\Android' -e '/Windows/c\Windows' -e '/MSIE/c\Windows' -e '/iPhone/c\iPhone' -e '/iPad/c\iPad' -e '/iPod/c\iPod' -e '/Macintosh/c\Mac' -e '/CrOS/c\Chrome OS' -e '/Linux/c\Linux' | sort | uniq -c | sort -nr | head -n8
254874 Android
183137 iPad
180046 Windows
136063 iPhone
30806 Mac
9807 Linux
6648 BlackBerry
3001 Chrome OSGraphing code:
#!/usr/env/python
import matplotlib.pyplot as plt
amounts = [int(a) for a in """254874
183137
180046
136063
30806
9807
6648
3001""".split()]
names = """Android
iPad
Windows
iPhone
Mac
Linux
BlackBerry""".split()
names.append("Chrome OS")
fig, ax = plt.subplots()
opacity = 0.4
error_config = {'ecolor': '0.3'}
x = range(len(amounts))
rects1 = plt.bar(x, amounts,
alpha=opacity,
color='b')
ax.set_xticks(x)
ax.set_xticklabels(names)
plt.xlabel('Device')
plt.ylabel('Pageviews')
plt.legend()
plt.tight_layout()
plt.show()[6] The command first does a little cleanup of the nasty things that end up sneaking into web requests, homogenises the data, and ranks it.
sed -e 's/"/index.cgi?l1=//' -e 's/"/index.cgi?l1=//' out | sed '/^"/d' | sed -e 's/&l.=//g' -e 's/&l..=//g' | sed -e 's/%3F/?/g' -e 's/%253F/?/g' | sed 's/?/./g' | sed 's/"//g' | sed '/^\s*$/d' | tr '[:lower:]' '[:upper:]' | sort | uniq -c | sort -n